Cel analizy korelacji Pearsona z perspektywy praktyka
Osoba sięgająca po korelację Pearsona ma zwykle bardzo konkretną intencję: sprawdzić, czy dwie zmienne liczbowo zmieniają się razem w sposób, który daje się opisać prostą linią. Chodzi o wstępne rozpoznanie wzorca, a nie o pełny model świata. Dobrze dobrana korelacja oszczędza czas, pozwala szybko odsiać przypadkowe zależności i wskazuje kierunek dalszej analizy.
Żeby tak było, trzeba jednak spełnić kilka warunków: dobrać odpowiedni typ zmiennych, upewnić się, że związek jest liniowy, skontrolować wpływ wartości odstających i nie mylić współwystępowania związków z przyczynowością. Korelacja Pearsona ma sens tylko wtedy, gdy te elementy grają ze sobą spójnie.
Czym jest korelacja Pearsona i do czego faktycznie służy
Definicja współczynnika korelacji r Pearsona
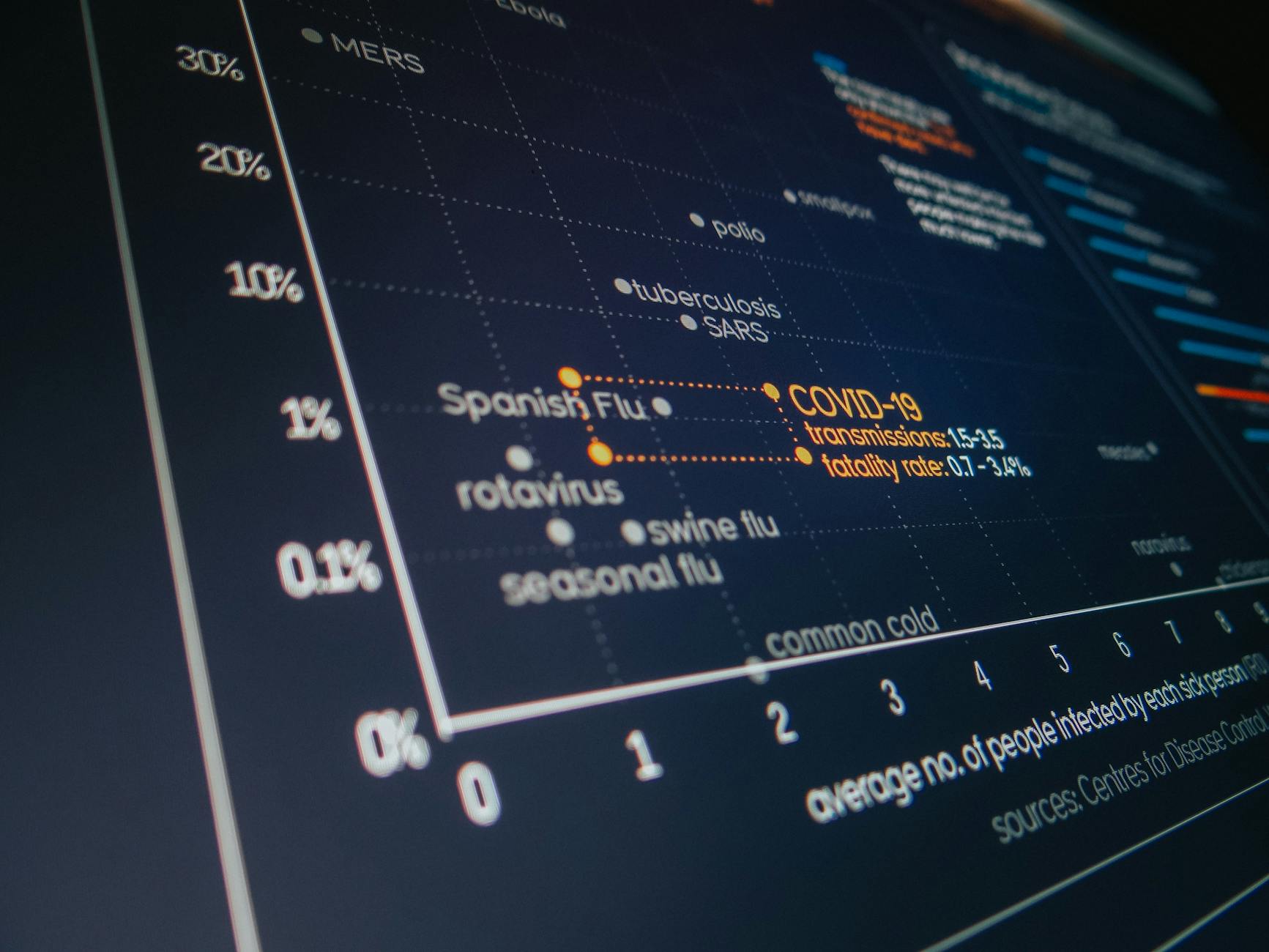
Korelacja Pearsona to współczynnik r, który mierzy siłę i kierunek liniowego związku między dwiema zmiennymi ilościowymi. Matematycznie jest to znormalizowana kowariancja: r przyjmuje wartości od -1 do +1.
W uproszczeniu:
r > 0 – im większa wartość X, tym średnio większa wartość Y (związek dodatni),
r < 0 – im większa wartość X, tym średnio mniejsza wartość Y (związek ujemny),
r ≈ 0 – brak liniowego związku (ale możliwe inne, nieliniowe zależności).
Współczynnik korelacji Pearsona jest liczony na podstawie odchyleń każdej obserwacji od średniej obu zmiennych. Dlatego r reaguje szczególnie mocno na punkty skrajne (obserwacje daleko od średniej) i na kształt całego rozkładu wyników.
Współwystępowanie zmian a związek przyczynowy
Korelacja Pearsona mierzy współwystępowanie zmian (co-occurrence), a nie to, czy jedna zmienna powoduje zmiany drugiej. R mówi jedynie: gdy rośnie X, Y ma tendencję do rośnięcia (lub maleje) – ale nie mówi dlaczego tak się dzieje.
Mogą wystąpić trzy podstawowe scenariusze:
X wpływa na Y (np. liczba godzin nauki wpływa na wynik testu),
Y wpływa na X (np. poziom stresu wpływa na liczbę dni chorobowych),
trzecia zmienna Z wpływa i na X, i na Y, generując korelację między nimi (np. sezonowość wpływa na wydatki reklamowe i przychody).
Bez dodatkowego kontekstu (dane czasowe, projekt eksperymentalny, modele przyczynowe) korelacja Pearsona nie rozstrzyga, który scenariusz jest prawdziwy. Ma sens jako narzędzie eksploracyjne, nie jako samodzielny dowód przyczynowości.
Korelacja Pearsona jest naturalnym wyborem wszędzie tam, gdzie pracuje się z ciągłymi danymi liczbowymi i szuka się prostych wzorców współzmienności. Przykłady zastosowań:
badania naukowe – związki między wynikami testów, pomiarami biomedycznymi, parametrami technicznymi,
analizy marketingowe – zależność między wydatkami reklamowymi a liczbą leadów, między liczbą wysłanych newsletterów a otwarciami,
finanse – współzależność zwrotów z różnych aktywów, związek między zmiennością kursu a wolumenem obrotu,
HR / people analytics – powiązanie liczby godzin szkoleń z wynikami ocen okresowych, relacja między stażem pracy a wynagrodzeniem.
W takich kontekstach korelacja Pearsona daje szybki sygnał, czy warto budować bardziej zaawansowane modele (np. regresję), czy związek jest zbyt słaby lub nieregularny, by poświęcać mu więcej uwagi.
Kiedy korelacja Pearsona jest pierwszym wyborem, a kiedy nie
Korelacja Pearsona ma sens jako narzędzie pierwszego wyboru, gdy spełnione są jednocześnie trzy warunki:
dwie zmienne o charakterze ilościowym (przedziałowe lub ilorazowe),
oczekiwany związek ma w przybliżeniu charakter liniowy,
nie mamy silnych powodów, by od razu podejrzewać ekstremalne wartości odstające lub bardzo silną skośność rozkładów.
Nie jest dobrym punktem startu, gdy:
zmienne są porządkowe (np. zadowolenie w skali 1–5) i liczba kategorii jest mała,
związek z definicji jest nieliniowy (np. efekt nasycenia, krzywa uczenia),
próbka jest bardzo mała (np. n=10) i pojedyncze obserwacje mogą całkowicie zdominować wynik,
obserwacje nie są niezależne (np. dane panelowe, wielu pracowników z jednej firmy bez kontroli na poziom firmy).
W takich sytuacjach lepiej rozważyć inne miary (np. korelację Spearmana) lub bardziej dopasowane modele, zamiast na siłę dopasowywać dane do korelacji Pearsona.
Warunki stosowania korelacji Pearsona – przegląd wymagań
Zmienne ilościowe: przedziałowe i ilorazowe
Korelacja Pearsona wymaga zmiennych ilościowych. Chodzi o skale, w których:
różnice mają sens liczbowy (np. różnica 10–20 jest taka sama jak 20–30),
można sensownie dodawać i odejmować wartości.
Wyróżnia się dwie kategorie:
skale przedziałowe (interval) – zero jest umowne, liczą się różnice (np. temperatura w °C),
skale ilorazowe (ratio) – zero oznacza brak cechy, można interpretować ilorazy (np. przychód, czas, wzrost).
Korelacja Pearsona działa dla obu typów. Problem pojawia się przy skalach porządkowych, np. typowej skali Likerta 1–5: „zdecydowanie się nie zgadzam” do „zdecydowanie się zgadzam”. Wiele analiz traktuje takie skale jako przybliżenie skali przedziałowej, ale:
odstępy między punktami skali nie muszą być równe psychologicznie (skok 4–5 bywa większy niż 2–3),
rozkłady często są mocno skupione przy krańcach (same 4–5 lub 1–2).
Przy dużych próbach i umiarkowanie symetrycznych rozkładach stosowanie korelacji Pearsona do skal Likerta bywa akceptowalne praktycznie, ale trzeba uczciwie zaznaczyć, że jest to przybliżenie. Przy silnie skośnych rozkładach lepiej rozważyć korelację rang Spearmana.
Założenie liniowości zależności
Korelacja Pearsona zakłada, że zależność między zmiennymi można sensownie przybliżyć prostą linią. Oznacza to, że:
zmiana X o stałą wartość wiąże się ze średnią, względnie stałą zmianą Y,
punkty na wykresie rozrzutu tworzą mniej więcej „chmurę” wokół linii prostej.
Kiedy związek jest krzywoliniowy (np. rosnący do pewnego momentu, a potem malejący), korelacja Pearsona może być bliska zeru, choć zależność jest w rzeczywistości bardzo silna. W takich przypadkach stosowanie r jest po prostu błędnym narzędziem.
Założenia rozkładowe: normalność reszt, nie gołych zmiennych
Często w podręcznikach pojawia się zdanie „korelacja Pearsona wymaga normalnego rozkładu zmiennych”. To zbyt uproszczone. Bardziej precyzyjnie:
dla samego oszacowania r normalność nie jest wymogiem absolutnym,
istotność statystyczna korelacji (test t dla r) opiera się na założeniu normalności rozrzutu wokół linii prostej, czyli w praktyce normalności reszt w modelu regresji liniowej.
Jeśli rozkłady zmiennych są lekkoskośne, a próba jest duża, testy oparte na r działają zwykle akceptowalnie. Kłopot zaczyna się przy:
silnych skośnościach (np. przychód, czas trwania sesji na stronie, liczba transakcji),
zgrupowanych danych (więcej niż połowa obserwacji ma te same wartości).
W takich sytuacjach lepiej pomyśleć o transformacji danych lub sięgnąć po metody mniej wrażliwe na rozkład, zanim zacznie się interpretować p-value dla korelacji Pearsona.
Homoscedastyczność: stała zmienność w całym zakresie
Homoscedastyczność oznacza, że rozrzut wartości Y wokół linii prostej jest mniej więcej taki sam dla małych i dużych wartości X. Gdy wariancja Y rośnie wraz z X (lub maleje), mamy do czynienia z heteroscedastycznością.
Dla samej wartości r heteroscedastyczność nie jest formalnym „złamaniem” algorytmu, ale może:
zaburzać interpretację siły związku (r „uśrednia” różne poziomy zmienności),
psuć testy istotności (błąd standardowy r jest źle oszacowany).
Jeżeli na wykresie rozrzutu chmura punktów przypomina lejek (wąsko przy małych X, szeroko przy dużych X), wniosek z korelacji powinien być formułowany ostrożniej, a w poważniejszych analizach trzeba rozważyć modele odporne na heteroscedastyczność (np. regresję z robust SE).
Niezależność obserwacji i problem danych zgrupowanych
Korelacja Pearsona zakłada, że każda obserwacja jest względnie niezależna od pozostałych. W praktyce to założenie jest łatwe do złamania, np. przy:
danych panelowych (wiele pomiarów tej samej osoby lub firmy),
danych zagnieżdżonych (pracownicy w firmach, uczniowie w klasach, klienci w regionach),
czasowych szeregach danych bez kontroli autokorelacji.
Jeśli np. liczysz korelację między wydatkami reklamowymi a przychodami na poziomie tygodni, a dane tygodnie są silnie skorelowane ze sobą (trend, sezonowość), to klasyczne r Pearsona może być przeszacowane. W takiej sytuacji zamiast prostego r trzeba rozważyć:
modele panelowe,
regresję z efektami stałymi / losowymi,
analizy różnicowe (np. korelacja przyrostów zamiast poziomów).
Źródło: Pexels | Autor: Sharad Bhat
Liniowość – kluczowe, a często ignorowane założenie
Co dokładnie oznacza liniowość w kontekście korelacji
Liniowość oznacza, że związek między X i Y da się dobrze przybliżyć funkcją w postaci Y = a + bX + błąd. Innymi słowy:
przyrost o 1 jednostkę X wiąże się średnio z przyrostem b jednostek Y, niezależnie od poziomu X,
jeśli narysujesz wykres rozrzutu, chmura punktów układa się mniej więcej wokół prostej.
Korelacja Pearsona „widzi” tylko taki typ zależności. Jeśli relacja jest krzywoliniowa, r staje się mylące. Może być niskie lub bliskie zeru mimo wyraźnego wzorca, bo dodatnie i ujemne fragmenty krzywej „znoszą się” w jednym współczynniku.
Silne związki nieliniowe z korelacją bliską zeru
Dobry przykład to relacja w kształcie litery U lub odwróconej U. Wyobraź sobie zmienną X (dawka bodźca) i Y (efekt). Przy małych dawkach efekt jest mały, przy średnich rośnie, a przy bardzo dużych spada (np. stres a produktywność). Na wykresie punkty układają się w łuk.
Jeśli policzysz r Pearsona dla wszystkich punktów naraz, dodatnie zależności w dolnej części łuku i ujemne w górnej części cząstkowo się znoszą, co daje wynik bliski 0. Interpretacja „brak związku” byłaby w tym przypadku po prostu błędna – związek jest, tylko nieliniowy.
Podobnie przy silnej saturacji: efekt rośnie z X bardzo szybko przy małych wartościach, a później się „wypłaszcza”. Korelacja Pearsona może być niższa, niż sugerowałaby faktyczna siła zależności w istotnym dla biznesu zakresie (np. przy niskich wydatkach marketingowych).
Jak wizualnie sprawdzić liniowość: wykres rozrzutu i linia trendu
Najprostszy sanity-check przed liczeniem korelacji Pearsona to wykres rozrzutu (scatterplot). Poziomo X, pionowo Y, każdy punkt to jedna obserwacja. Potem dodajesz:
prostą linię trendu (najprostsza regresja liniowa),
opcjonalnie krzywą wygładzającą (np. LOESS / LOWESS), by zobaczyć ewentualną nieliniowość.
Jeżeli:
wygładzona krzywa prawie pokrywa się z linią prostą – liniowość jest w porządku,
widać wyraźny łuk, literę U, S lub inne zakrzywienia – korelacja Pearsona będzie niedoskonałym opisem.
Uwaga: przy małej próbie (np. n=20–30) ocena „na oko” bywa złudna. Punktów jest mało, więc można łatwo przeoczyć nieregularności. Im więcej danych, tym bardziej obowiązkowy jest scatterplot przed interpretacją r.
Proste testy „na oko” i minimalny sanity-check
Praktyczne heurystyki oceny liniowości
Przy roboczej analizie trudno za każdym razem sięgać po formalne testy. W praktyce wystarcza kilka prostych heurystyk:
podziel wykres rozrzutu na 3–4 pionowe „pasy” (np. kwartyle X) i mentalnie oszacuj średnią Y w każdym z nich – jeśli średnie rosną mniej więcej liniowo, jest dobrze,
sprawdź, czy wygładzona krzywa (LOESS) nie „ucieka” od prostej trendu o stały znak (np. cały czas powyżej albo poniżej) – duże odchylenia sugerują nieliniowość,
narysuj dodatkowo wykres reszt (Y – ŷ z regresji liniowej) względem X – wzór w kształcie litery U, S lub wachlarza jest sygnałem alarmowym.
Jeżeli dwa z trzech powyższych testów „na szybko” wskazują problem, korelacja Pearsona powinna być traktowana najwyżej jako bardzo zgrubny opis zależności, a nie główny dowód wniosku.
Kiedy prosty model liniowy wystarcza mimo lekkiej nieliniowości
Nie każda krzywizna dyskwalifikuje r Pearsona. Liczy się skala zniekształcenia względem celu analizy. Jeśli:
nieliniowość jest widoczna głównie na krańcach rozkładu, a kluczowy zakres biznesowy leży w środku,
model liniowy daje poprawne kierunki i sensowną kolejność (kto ma wyższe Y przy wyższym X),
nie budujesz na tej korelacji prognoz punktowych, tylko ogólny obraz współzmienności,
to stosowanie r może być pragmatycznie akceptowalne. Trzeba jednak jasno sygnalizować, że opisujesz związek „w przybliżeniu liniowy” i że skrajne wartości mogą zachowywać się inaczej niż sugeruje prosta.
Typowe błędy interpretacji korelacji Pearsona
Korelacja ≠ przyczynowość
Najbardziej klasyczny błąd to utożsamianie korelacji z relacją przyczynową. r > 0.7 wygląda „kusząco”, ale sam współczynnik nie mówi nic o kierunku wpływu ani o tym, czy wpływ w ogóle istnieje.
Źródła złudnej przyczynowości są dość powtarzalne:
zmienna trzecia (confounder) – X i Y są powiązane tylko dlatego, że oba zależą od Z (np. korelacja między liczbą strażaków na akcji a wysokością strat: im większy pożar, tym więcej strażaków i większe straty – przyczyną jest rozmiar pożaru),
odwrotny kierunek – faktycznie to Y wpływa na X (np. wyższe przychody firmy zwiększają budżet marketingowy, a nie odwrotnie),
sprzężenie zwrotne – X wpływa na Y, a Y z kolei na X (np. popularność produktu zwiększa liczbę opinii, a opinie zwiększają popularność).
Korelację można traktować jako wskazówkę hipotezy przyczynowej, nigdy jako jej dowód. Do wniosków przyczynowych potrzebny jest inny aparat: eksperymenty, modele przyczynowe, kontrola zmiennych zakłócających.
Wysoka korelacja przy silnym wpływie zmiennej trzeciej
Częsty scenariusz: dwie zmienne biznesowe mają bardzo wysoką korelację, bo obie są mocno zdeterminowane przez wspólny czynnik. Przykład z praktyki produktowej: liczba aktywnych użytkowników (X) i liczba zgłoszeń do supportu (Y). Korelacja jest prawie idealna, ale głównym „sterownikiem” jest baza użytkowników, nie np. jakość produktu.
Minimalny test na „zmienną trzecią” przy pracy z r Pearsona:
zastanów się, czy obie zmienne nie są w oczywisty sposób rosnącą funkcją jakiegoś prostego parametru (czas, liczba klientów, liczba transakcji),
jeśli tak, policz korelację na wskaźnikach względnych (np. zgłoszenia na użytkownika zamiast gołej liczby zgłoszeń) albo użyj korelacji cząstkowej (partial correlation), kontrolując ten czynnik.
Tip: często samo przeliczenie wartości „per user”, „per session” czy „per 1000 odwiedzin” drastycznie zmienia korelacje i prowadzi do trzeźwiejszych wniosków.
Ignorowanie wpływu zakresu danych (range restriction)
Siła korelacji jest wrażliwa na zakres obserwowanych wartości. To efekt tzw. ograniczenia rozpiętości (range restriction). Mechanizm jest prosty: jeśli w próbie widzimy tylko wąski wycinek możliwych wartości X, zmienność jest sztucznie mała, a r Pearsona jest często zaniżone.
Typowe źródła tego efektu:
badanie tylko najlepszych kandydatów (np. korelacja między wynikami testu a efektywnością pracy wśród już zatrudnionych, a nie wszystkich aplikujących),
analiza tylko „aktywnych” klientów, bez osób, które szybko odpadają,
obejrzenie tylko jednego segmentu rynku (np. tylko duże firmy, tylko klienci premium).
Jeżeli korelacja wydaje się podejrzanie niska względem zdrowego rozsądku lub badań z literatury, pierwsze pytanie brzmi: czy zakres X (i Y) nie jest przypadkiem przycięty przez sposób doboru próby?
Korelacja na danych zagregowanych vs jednostkowych
Analizowanie korelacji na poziomie zagregowanym (grupy, regiony, dni tygodnia) potrafi dramatycznie zmienić obraz zależności względem analizy na poziomie jednostki. To klasyczna ekologiczna pułapka korelacji (ecological fallacy).
Przykład: korelacja między średnim poziomem edukacji w regionie a średnim dochodem regionu zwykle jest wysoka. Nie oznacza to jednak, że na poziomie jednostki każda dodatkowa klasa szkoły przekłada się na identyczny wzrost dochodu – wewnątrz regionu zależność może być słabsza lub zaburzona innymi czynnikami.
Przy interpretacji r zawsze warto zadawać sobie dwa pytania:
na jakim poziomie są dane (osoby, produkty, firmy, regiony, dni, miesiące)?,
czy wniosek, który wyciągam, dotyczy tego samego poziomu, czy „przeskakuję” poziomy (z regionów na osoby, z dni na użytkowników)?
Mylenie korelacji Pearsona z korelacjami rangowymi
Korelacja Pearsona działa na wartościach liczbowych i mierzy zależność liniową. Korelacje rangowe (Spearmana, Kendalla) działają na rangach i mierzą zależność monotoniczną (rosnącą lub malejącą, niekoniecznie liniową).
Błędy zaczynają się wtedy, gdy:
r Pearsona jest niski, ale korelacja Spearmana wysoka – wyciągany jest wniosek „dane się wykluczają”, zamiast uznać, że mamy relację wyraźnie nieliniową,
na odwrót: r Pearsona wysoki, a rangowy niski – co sugeruje, że związek opiera się na kilku skrajnych obserwacjach, a porządek większości danych jest słabo skorelowany.
Sensowna praktyka: przy danych z podejrzeniem nieliniowości lub obecnością outlierów równolegle liczyć korelację Pearsona i Spearmana, a różnicę między nimi traktować jako „czujnik problemów” z założeniami.
Rola obserwacji odstających (outlierów) w korelacji Pearsona
Jak pojedynczy punkt potrafi „zepsuć” korelację
r Pearsona jest wrażliwe na outliery, szczególnie gdy leżą daleko w poziomie (X) lub pionie (Y), a najlepiej w obu kierunkach jednocześnie. Jeden taki punkt może:
podnieść korelację z bliskiej zera do „imponującej”,
albo niemal całkowicie ją zniszczyć – w zależności od położenia.
Mechanizm jest geometryczny: korelacja to w istocie znormalizowane współwahanie. Ekstremalne wartości generują duży wkład do kowariancji, więc ich orientacja względem chmury punktów decyduje o kierunku i wielkości r.
Diagnostyka wpływowych obserwacji
Przy poważniejszej analizie korelacji dobrym minimum jest szybkie sprawdzenie wpływowych punktów za pomocą narzędzi z regresji liniowej:
leverage – jak daleko punkt leży w poziomie (X) od środka danych,
studentized residuals – jak silnie punkt odbiega w pionie (Y) od prostej regresji,
Cook’s distance – łączy oba efekty i pokazuje, jak bardzo punkt „ciągnie” dopasowanie.
Jeśli kilka punktów ma bardzo wysoką wartość Cook’s distance, dopuszczalne są trzy kroki:
sprawdzić, czy nie ma błędów w danych (literówki, złe jednostki, zduplikowane rekordy),
zastanowić się, czy tak skrajne wartości należą do tej samej „populacji” (np. inny typ klienta, inny kanał sprzedaży),
policzyć korelację z i bez tych punktów i porównać wnioski.
Strategie pracy z outlierami a korelacja
Usuwanie outlierów „bo psują korelację” jest prostą drogą do autopotwierdzania hipotez. Bezpieczniejsze są techniki, które ograniczają wpływ skrajnych wartości bez ich całkowitego wyrzucania:
winsoryzacja – przycięcie skrajnych wartości do np. 1. i 99. percentyla (X i Y),
transformacje – logarytm, pierwiastek, transformacje Box–Coxa dla zmiennych dodatnich,
korelacje odporne – np. korelacja biwektorowa lub M-estymatory, które „ignorują” skrajnie odległe punkty.
Po takim przetworzeniu r Pearsona lepiej odzwierciedla główny wzorzec, a nie pojedyncze anomalie pomiarowe czy niszowe przypadki.
Źródło: Pexels | Autor: RDNE Stock project
Współczynniki korelacji jako element szerszego modelu
Korelacja cząstkowa: kontrola zmiennej trzeciej
Kiedy pojawia się podejrzenie, że X i Y są skorelowane głównie przez Z, prostym rozszerzeniem jest korelacja cząstkowa (partial correlation). Mierzy ona związek X–Y po „wyjęciu” liniowego wpływu Z z obu zmiennych.
Technicznie sprowadza się to do:
zbudowania dwóch regresji liniowych: X ~ Z oraz Y ~ Z,
wzięcia reszt z tych modeli (X_res, Y_res),
policzenia klasycznej korelacji Pearsona między X_res i Y_res.
Interpretacja: jak bardzo X i Y są powiązane, gdy porównujemy obserwacje o podobnym poziomie Z. To prosty sposób na odsianie korelacji generowanych przez oczywiste zmienne tła, np. czas, liczbę użytkowników, wiek.
Macierz korelacji a problem wielokolinearności
Przy wielu zmiennych macierz korelacji jest często pierwszym krokiem eksploracji. Pojawia się wtedy drugi aspekt: wielokolinearność (wysokie korelacje między predyktorami). Z perspektywy korelacji Pearsona ważne są dwa punkty:
jeżeli dwie zmienne wyjaśniające mają r bliskie 1, modele wielowymiarowe (np. regresja) będą miały niestabilne współczynniki – korelacje „uprzedzają” ten problem,
silne korelacje wewnątrz grup zmiennych sugerują, że można je zastąpić mniejszą liczbą komponentów (np. PCA) albo wybrać jedną reprezentatywną zmienną.
Macierz korelacji nie jest więc tylko kolorowym „heatmapem”. To realne narzędzie diagnostyczne pod kątem stabilności późniejszych modeli i sensownego doboru cech.
Korelacja jako wstęp do prostych modeli prognostycznych
Jeżeli korelacja Pearsona między X i Y jest wysoka i założenia w przybliżeniu spełnione, naturalnym kolejnym krokiem jest regresja liniowa Y ~ X. W prostym modelu jednowymiarowym:
r² (kwadrat korelacji) mówi, jaki odsetek wariancji Y jest wyjaśniany przez liniową zależność od X,
współczynnik b (nachylenie) przekłada związek na bardziej „użyteczną” skalę (przyrost jednostek Y na jednostkę X).
Sama korelacja mówi „te dwie zmienne współwahają się tak a tak”, regresja odpowiada dodatkowo na pytanie „o ile średnio zmienia się Y, gdy X rośnie o 1 jednostkę”. W wielu zastosowaniach biznesowych dopiero ten drugi krok ma bezpośredni sens decyzyjny.
Specyficzne pułapki korelacji Pearsona w danych biznesowych i produktowych
Trend w czasie a korelacja „wszystko z wszystkim”
W danych czasowych (time series) ogromna część korelacji wynika po prostu z tego, że wiele wskaźników rośnie lub maleje z czasem. Przykład: liczba użytkowników aplikacji, liczba transakcji, koszty serwera – wszystkie rosną, więc korelacje między nimi są wysokie, nawet jeśli nie ma żadnego sensownego powiązania przyczynowego.
Aby sprawdzić, czy korelacja nie jest wyłącznie skutkiem trendu, można:
usunąć trend z obu szeregów (np. przez odejmowanie średniej kroczącej) i policzyć korelację na odtrendowanych resztach,
policzyć korelację na przyrostach (różnicach między kolejnymi okresami), nie na surowych poziomach.
Sezonowość, cykle i opóźnienia między zmiennymi
Szeregi czasowe oprócz trendu mają często sezonowość (powtarzalne wzorce: dni tygodnia, miesiące, sezony) i opóźnienia (lag) między reakcją jednej zmiennej na drugą. Korelacja „na surowo” tego nie odróżnia.
Przykład z produktu: kampania marketingowa podbija ruch w aplikacji w weekend, a sprzedaż w sklepie rośnie w poniedziałek–wtorek. Korelacja liczby wizyt z bieżącą sprzedażą może być niska, ale korelacja „wizyty z tygodnia t” vs „sprzedaż z tygodnia t+1” już wysoka.
Kilka prostych testów dla szeregów czasowych:
policz korelacje opóźnione (cross-correlation) X(t) z Y(t+k) dla kilku opóźnień k – szczyt wartości często pokazuje realistyczne opóźnienie reakcji,
rozbij serię na komponenty: trend, sezonowość, reszta (np. klasyczne STL) i policz korelację na resztach – usuwasz w ten sposób zarówno długoterminowy trend, jak i stałe sezonowe „fale”,
sprawdź korelację w poszczególnych podokresach (np. kwartałach) – silna, ale tylko w jednym sezonie, bywa mniej użyteczna niż stabilna, średnia korelacja przez cały rok.
Jeśli korelacja znika po usunięciu sezonowości lub trendu, związek może być głównie kalendarzowy, a nie behawioralny.
Efekt skali: korelacje na licznikach vs stawkach i wskaźnikach
W danych biznesowych surowe liczniki (count) często rosną, bo rośnie skala: więcej użytkowników, więcej produktów, więcej ruchu. Korelacje między licznikami w dużej części opisują więc jedną zmienną: „wielkość biznesu” lub „wielkość konta”.
Typowy błąd: korelacja liczby wysłanych powiadomień push z liczbą transakcji. Im większa baza, tym więcej powiadomień i więcej transakcji, więc r jest wysoki. Wniosek „push działa” jest wtedy mocno przeszacowany.
Lepsze podejście to przejście z liczników na wskaźniki:
CTR (click-through rate) zamiast liczby kliknięć,
konwersja (transakcje/odsłony) zamiast liczby transakcji,
ARPU (average revenue per user) zamiast łącznego przychodu.
Korelacje między wskaźnikami przybliżają realne zależności zachowań, a nie tylko efekt „duży klient robi wszystkiego więcej”. Często po tej zmianie r istotnie spada – co jest zdrowszym opisem rzeczywistości.
Efekt mieszania kanałów i segmentów
Silne korelacje między metrykami potrafią wynikać wyłącznie z miksu segmentów klientów lub kanałów. Łączna korelacja „wszystko w jednym worku” bywa efektem tego, że jedna grupa ma wysokie wartości obu zmiennych, a druga niskie – wewnątrz grup zależność jest o wiele słabsza.
Przykładowy schemat:
segment A: małe firmy, niskie wydatki, mała liczba użytkowników,
segment B: duże firmy, wysokie wydatki, duża liczba użytkowników.
Na całej próbie korelacja między wydatkiem a liczbą użytkowników jest bliska 1. Gdy policzysz korelacje osobno w A i B, okazuje się, że wewnątrz segmentów to już dużo bardziej rozproszona chmura punktów.
Dobry nawyk przy korelacjach w danych biznesowych:
policz r na całej próbie,
następnie osobno w najważniejszych segmentach (kraj, typ klienta, kanał akwizycji, plan taryfowy),
porównaj: jeśli korelacja „rozpada się” po rozbiciu na segmenty, główny efekt jest segmentowy, nie ciągły.
Korelacja na poziomie użytkownika vs sesji vs zdarzeń
W produktach cyfrowych istotny jest poziom agregacji: użytkownik, sesja (wizyta), zdarzenie (event). Korelacje liczone na różnych poziomach odpowiadają na zupełnie inne pytania, choć nazwy tych samych metryk mogą brzmieć identycznie.
Przykład:
poziom użytkownika: korelacja między średnią długością sesji użytkownika a jego miesięcznym przychodem,
poziom sesji: korelacja między długością konkretnej sesji a prawdopodobieństwem zakupu w tej sesji.
Te dwie korelacje mają inną interpretację. Pierwsza mówi, czy „typowo dłużej siedzący użytkownicy” płacą więcej. Druga – czy „konkretne dłuższe sesje” mają wyższe szanse na zakup. Mieszanie tych poziomów prowadzi do pozornych paradoksów (np. efekt Simpsonów).
Tip: zawsze zapisuj jawnie, jaki jest poziom jednostki analizy (user_id, session_id, order_id) i upewnij się, że wniosek odnosi się do tego samego poziomu.
Korelacja a testy A/B: złe użycie i lepsze alternatywy
W eksperymentach A/B kusi, by w ramach jednego wariantu liczyć korelacje między wieloma metrykami i z tego wyciągać historyjki („w wariancie B wzrosła korelacja między czasem w aplikacji a konwersją, więc użytkownicy są bardziej zaangażowani”). Problem: korelacja nie jest głównym obiektem losowania w A/B, a próba per wariant często jest za mała, aby stabilnie szacować r.
Bezpieczniejsze schematy:
jeżeli interesuje cię „siła powiązania” między X i Y zależna od wariantu, porównuj współczynniki regresji (model z interakcją: Y ~ X * wariant), zamiast gołej korelacji,
traktuj korelację jako pomocniczy opis w dużych próbach, ale nie jako główną metrykę sukcesu,
jeśli musisz porównać korelacje między grupami, użyj formalnych testów (np. test Fishera z transformacją z = atanh(r)), zamiast „na oko”.
Korelacja w A/B może być użyteczna diagnostycznie (czy związek X–Y zmienił się jakościowo), ale decyzje o wygranym wariancie lepiej opierać na różnicach w oczekiwanych wartościach metryk, nie na samym r.
Przy danych realnych niemal zawsze pojawiają się brakujące wartości. Standardowe implementacje korelacji (np. w R, Pandas) najczęściej robią pairwise complete: liczą r na parach obserwacji, w których X i Y są jednocześnie niepuste. To domyślne zachowanie ma kilka konsekwencji:
efektywna próba dla pary (X, Y) może być dużo mniejsza niż liczba rekordów w tabeli,
różne pary zmiennych mogą być liczone na innych podpróbach, co utrudnia porównywanie r między parami,
jeśli brak danych nie jest losowy (MNAR), korelacja może być systematycznie przeszacowana lub niedoszacowana.
Przy bardziej odpowiedzialnej analizie korelacji:
raportuj liczbę par (N) dla każdej korelacji,
rozważ imputację braków (np. wielokrotną) i liczenie korelacji na pełnych danych,
sprawdź, czy brak X lub Y nie zależy od ich wartości (np. wysokie wydatki częściej nie raportowane).
Druga rzecz to ważenie obserwacji. Dane ankietowe czy logi z próbkowania (sampling) często wymagają wag, aby odzwierciedlić populację. Klasyczna korelacja Pearsona zakłada równą wagę każdej obserwacji; przy wagach powinno się liczyć ważoną kowariancję i ważone odchylenia standardowe. Użycie zwykłego r na danych ważonych „po cichu” zmienia pytanie z „jaka jest korelacja w populacji” na „jaka jest korelacja w tej konkretnie zebranej próbie”.
Stabilność oszacowania korelacji przy małych próbach
r Pearsona bywa zaskakująco niestabilne przy małych N. Dwie próby po 20–30 obserwacji z tej samej populacji potrafią dać r = 0.1 i r = 0.6 tylko przez losowe fluktuacje. Z tego powodu:
dla bardzo małych prób (np. N < 30) r traktuj bardziej jako „sugestię kierunku” niż twardą liczbę,
patrz na przedział ufności dla r (np. wyliczony z użyciem transformacji Fishera z = atanh(r)),
unikaj budowania skomplikowanych interpretacji na podstawie różnic r w małych próbach, jeśli przedziały ufności nachodzą na siebie.
Uwaga: test istotności korelacji (p-value) w małych próbach ma swoje własne problemy – łatwo o brak mocy testu. Korelacja r = 0.4 w próbie 20 osób może nie wyjść „istotna statystycznie”, choć w praktyce jest to już sensowna siła związku.
Normalność rozkładów a testowanie korelacji
Często powtarzane wymaganie „dla korelacji Pearsona obie zmienne muszą mieć rozkład normalny” jest uproszczeniem. Dla samego oszacowania r normalność nie jest konieczna – ważniejsze są liniowość i brak silnych outlierów. Normalność pojawia się w kontekście:
testowania istotności korelacji (dokładność rozkładu statystyki t zależy od założeń),
budowy przedziałów ufności w bardzo małych próbach.
Praktyczny kompromis:
jeśli rozkłady są wyraźnie skośne, a pojawiają się outliery, najpierw transformuj (log, sqrt) lub użyj korelacji rangowej do weryfikacji wniosku,
dla dużych prób (setki, tysiące obserwacji) centralne twierdzenie graniczne „wygładza” wiele naruszeń normalności – geometryczna interpretacja r jest wtedy nadal sensowna, ale p-value trzeba czytać z większym dystansem.
Dwie zmienne, wiele pomiarów: powtarzane obserwacje i dane panelowe
Klasyczne r zakłada, że obserwacje są niezależne. W danych panelowych (np. ci sami użytkownicy mierzeni co tydzień) to założenie jest naruszone. Liczenie korelacji „po prostu na wszystkich punktach” miesza w sobie:
zróżnicowanie między jednostkami (różne średnie poziomy X i Y),
zróżnicowanie w czasie wewnątrz jednostki (odchylenia od jej średniej).
Dwa sensowne warianty analizy:
korelacja międzyosobnicza (between): policz średnie X̄_i, Ȳ_i dla każdej jednostki i korelację między tymi średnimi – odpowiada na pytanie: „czy jednostki z wyższym X mają zwykle wyższy Y?”.
korelacja wewnątrzosobnicza (within): dla każdej jednostki odejmij jej średnią (X_it – X̄_i, Y_it – Ȳ_i) i policz korelację na tak przetransformowanych danych – pytanie: „czy gdy X danej jednostki jest wyższe niż zwykle, to Y też jest wyższe niż zwykle?”.
Te dwie korelacje mogą mieć różne znaki. Typowy przypadek: kraje bogatsze (wyższe średnie dochody) mają wyższe wydatki zdrowotne (dodatnia korelacja between), ale wzrost wydatków w czasie w obrębie danego kraju wcale nie przekłada się liniowo na poprawę mierzonego wskaźnika zdrowia (słaba lub zerowa korelacja within).
Kiedy korelacja Pearsona nie jest właściwym narzędziem
Zależności nieliniowe, progi i efekty saturacji
Korelacja Pearsona „widzi” tylko linię prostą. Jeśli zależność ma kształt progowy, logistyczny albo odwróconej litery U, r potrafi być bliskie zera mimo bardzo silnego, deterministycznego związku.
Przykłady z praktyki produktowej:
czas ładowania strony vs konwersja: do pewnego progu pogorszenie czasu ładowania prawie nie szkodzi, potem nagle konwersja zaczyna gwałtownie spadać – efekt progowy,
liczba powiadomień push vs retencja: mała liczba notyfikacji zwiększa powroty, ale po przekroczeniu pewnej częstotliwości użytkownicy zaczynają się irytować i odinstalowują aplikację – efekt odwróconej litery U.
W takich sytuacjach korelacja Pearsona często maskuje faktyczny problem. Sensowniejsze narzędzia:
wykres punktowy z dopasowaniem nieliniowym (LOESS, splajny),
modele nieliniowe lub z interakcjami (np. regresja z terminami kwadratowymi X²),
analiza segmentowa: korelacje w przedziałach X (niski, średni, wysoki poziom).
Dane kategoryczne, porządkowe i „prawie liczbowe”
Korelacja Pearsona wymaga zmiennych ilościowych w sensownym znaczeniu: odległość między 1 a 2 powinna mieć ten sam sens jak między 4 a 5. Dla zmiennych kategorycznych lub czysto porządkowych (rankingi, oceny w skali Likerta) ta interpretacja jest co najmniej wątpliwa.
Typowe pułapki:
liczenie r między krajem (zakodowanym jako 1, 2, 3, …) a dowolną metryką – to arbitralna numeracja, a nie skala,
traktowanie ocen 1–5 jako idealnie interwałowych, choć percepcyjnie odstęp między 4 a 5 bywa inny niż między 1 a 2.
Lepsze zamienniki:
Najczęściej zadawane pytania (FAQ)
Kiedy mogę użyć korelacji Pearsona, a kiedy lepsza jest korelacja Spearmana?
Korelacja Pearsona jest pierwszym wyborem, gdy masz dwie zmienne ilościowe (przedziałowe lub ilorazowe), związek między nimi jest w przybliżeniu liniowy, a dane nie są skrajnie skośne i bez pojedynczych, dominujących obserwacji. Dobrze sprawdza się np. dla wzrostu i masy ciała, przychodu i kosztów, czasu nauki i wyniku testu.
Korelacja Spearmana (rang) jest bezpieczniejsza, gdy:
zmienne są porządkowe (np. skala 1–5 zadowolenia),
podejrzewasz związek nieliniowy, ale monotoniczny (w miarę rosnący lub malejący),
masz silne wartości odstające lub bardzo skośne rozkłady (np. przychody klientów).
Tip: jeśli wykres rozrzutu nie przypomina „chmury wokół prostej”, a bardziej zakrzywioną ścieżkę, sprawdź Spearmana zamiast Pearsona.
Czy do korelacji Pearsona potrzebny jest normalny rozkład danych?
Do samego obliczenia współczynnika r normalność rozkładu zmiennych nie jest konieczna. Algorytm działa także przy lekkiej skośności i rozkładach dalekich od idealnej gaussowskiej „dzwonowej” krzywej. Problem zaczyna się wtedy, gdy chcesz testować istotność statystyczną r (p-value, przedziały ufności).
Test istotności dla korelacji Pearsona opiera się na założeniu normalności reszt wokół linii regresji, a nie „gołych” zmiennych. Przy dużych próbach lekkie odchylenia od normalności zwykle nie są krytyczne. Przy bardzo skośnych rozkładach lub zgrupowanych danych (wiele identycznych wartości) warto rozważyć:
transformację zmiennych (np. log, sqrt),
użycie miar nieparametrycznych, np. korelacji Spearmana.
Uwaga: jeśli histogram zmiennej przypomina „ogon smoka” zamiast symetrycznej górki, wynik testu dla Pearsona może być mylący.
Czy wysoka korelacja Pearsona oznacza związek przyczynowy?
Nie. Korelacja Pearsona mierzy współwystępowanie zmian (kiedy X rośnie, Y ma tendencję do rośnięcia lub maleje), ale nic nie mówi o tym, czy X powoduje Y. Wysokie r może wynikać z kilku scenariuszy: X wpływa na Y, Y wpływa na X albo obie zmienne są sterowane przez trzecią zmienną Z (np. sezonowość, trend rynkowy).
Przykład: wydatki reklamowe i przychody zwykle są dodatnio skorelowane, ale często obie te wielkości rosną po prostu w „dobrych” miesiącach sprzedażowych. Korelacja sama nie powie, na ile wynik to efekt reklamy, a na ile kalendarza (świąt, sezonu). Do wniosków przyczynowych potrzebujesz dodatkowego projektu badania (eksperyment, dane panelowe, modele przyczynowe), a nie tylko wysokiego r.
Czy mogę liczyć korelację Pearsona dla skali Likerta 1–5?
Formalnie skala Likerta (1–5, „zdecydowanie się nie zgadzam” – „zdecydowanie się zgadzam”) jest skalą porządkową, a nie ilościową. Algorytm Pearsona zakłada sensowne różnice liczbowe między punktami, a w Likercie odstęp 4–5 psychologicznie bywa inny niż 2–3. Dlatego z punktu widzenia teorii statystyki to przybliżenie, nie idealne zastosowanie.
W praktyce, przy dużych próbach i w miarę symetrycznych rozkładach odpowiedzi (bez mocnego „przyklejenia” tylko do 1 i 5) badacze często stosują korelację Pearsona dla skal Likerta i akceptują to jako przybliżenie. Gdy rozkład jest mocno skośny (np. prawie same 4 i 5), lepiej użyć korelacji Spearmana, która operuje na rangach, a nie na samych wartościach liczbowych.
Jak sprawdzić, czy zależność jest liniowa przed użyciem korelacji Pearsona?
Najprostsza i najskuteczniejsza metoda to wykres rozrzutu (scatterplot). Na osi X umieszczasz pierwszą zmienną, na osi Y drugą. Jeśli punkty tworzą „chmurę” wokół wyraźnej linii prostej (rosnącej lub malejącej), założenie liniowości jest w przybliżeniu spełnione. Jeśli widzisz łuk, literę U, odwróconą U lub inne krzywe – związek nie jest liniowy.
Dodatkowe sygnały, że liniowość jest naruszona:
r jest bliski zeru, ale na wykresie widać wyraźny wzorzec (np. rośnie, potem spada),
po „odcięciu” części danych korelacja zmienia się dramatycznie,
reszty z prostej regresji (Y prognozowane z X) mają wyraźny, systematyczny kształt zamiast losowego szumu.
Tip: jeśli wykres rozrzutu pokazuje krzywą, rozważ transformacje (np. logarytmiczną) lub modele nieliniowe zamiast korelacji Pearsona.
Jak wartości odstające wpływają na korelację Pearsona i co z nimi zrobić?
Korelacja Pearsona bazuje na odchyleniach od średniej, przez co pojedyncze punkty skrajne (outliery) mogą znacząco zwiększyć lub obniżyć r, a czasem wręcz odwrócić znak korelacji. Jeden bardzo nietypowy klient, bardzo długi czas sesji lub ekstremalny pomiar techniczny potrafi „wyciągnąć” linię i dać złudzenie silnej zależności lub je zamaskować.
Praktyczna ścieżka postępowania:
zrób wykres rozrzutu i poszukaj punktów daleko od „chmury”,
sprawdź, czy to błąd pomiaru/wnoszenia danych (jeśli tak – popraw lub usuń),
jeśli to realne wartości, policz korelację z nimi i bez nich; porównaj wyniki,
rozważ bardziej odporną miarę (Spearman, korelacje odporne) lub analizę z osobnym modelem dla „typowych” i „nietypowych” obserwacji.
Uwaga: mechaniczne usuwanie wartości odstających tylko dlatego, że „psują korelację”, prowadzi do błędnych wniosków. Najpierw trzeba zrozumieć ich źródło.
Dlaczego korelacja Pearsona bliska zeru nie zawsze oznacza brak związku?
Korelacja Pearsona mierzy wyłącznie liniowy związek między zmiennymi. Jeśli zależność jest nieliniowa (np. efekt nasycenia, krzywa uczenia, relacja w kształcie U), r może być bliski zeru, mimo że zmienne są silnie powiązane w inny sposób. W takim scenariuszu różne fragmenty krzywej „znoszą się” przy liczeniu znormalizowanej kowariancji.











{kind=link}